ありきたりなworld
面倒なことは後回しにしてまずは画面に文字を表示させてみましょう。
え?なんでHello Worldじゃないんだ?私printf関数を使うって聞いたんだけどputsって何?いやいや、こっちのほうがありきたり(普通)ですから。(なぜprintfでなくputsを使ったのかは後で説明します)
このコードから多くのことが学べます。まずは一行目。
#include<stdio.h>
これはヘッダーファイルと呼ばれるものを読み込む部分です。stdio.hはC言語が提供する標準ライブラリで、標準入出力(STanDard Input and Output)に関わる関数群を提供します。puts関数とかprintf関数はこれを読み込むことで使えるようになります。
ついで2行目と4行目に注目してください。
int main(void){
puts("arikitari na world!");//画面に表示
return 0;
}
C/C++言語は必ず関数があり、特に別途定めない限りmain関数から処理が始まります。詳細説明は先送りするとして関数には戻り値というものがあり、void型以外では必ず戻り値を返す必要があります。
main関数の戻り値は、プログラムの処理がmain関数から始まるため、プログラムの終了コード(Exist Code)とも呼ばれます。処理が成功した場合は0を返す(return 0;)のが慣習となっています。
main関数の書き方
main関数ですが、ANCI-C規格で書き方が決まっています。(非フリースタンディング環境の場合)
int main(void);
int main(int argc, char* argv[]);
int main()
1行目は引数を無視する書き方で、2行目は引数(関数の解説の章で解説します)を受け取るときの書き方、3行目はC++のmain関数の引数を受け取らない書き方となり、C99でも認められます。
というわけでmain関数は上記何れかの書き方で書きましょう、というお話です。個人的にはちゃんとvoidと書きたい派です。
まちがっても
main();
void main(void);
などとしてはいけません(前者は古いCの記法、後者は頭がおかしい書き方)。
コメントの書き方
今はこんなに短いプログラムですから、必要性は薄いですが、もっと大規模に慣ればなるほど、ソースコードにメモを書きたくなります。すでにさらっと使っていますが、書き方は2通りあります。
/*これは行をまたがって使えるコメント*/
//これはその行の終わりまでコメントになる
2行目がANCI-C認められたのはC99からなんですが、ほとんどのコンパイラーが対応してましたからどんどんつかって構いません。
注意点ですが、一行目の書き方のコメントはネスト(入れ子)にできません
/*これはコメント
/*ここもコメントだけど*/
ここはコメントじゃない*/
稀によくあるミスなので注意です。だから私はコメントを書くときは基本的に2行目のいわゆる行コメントを使うのをおすすめします。
変数と代入
プログラミング言語で必ずあるものといえば、真っ先に変数が上がるでしょう。変数とは処理途中のデータ(数字など)を保管しておく箱(オブジェクト)のようなものです。
int a;
a = 10;
int numof_allocated_array_at_a_time = 15;
char ch = getchar();
1行目では変数を宣言し定義しています。宣言は「こんな変数があるよ」とコンパイラに教える作業で、定義は「ここで変数を確保するよ」とコンパイラに教えることです。
定義して初めてメモリ上に実体を持ち、変数を使えるようになるわけです。が、とりあえずヘッダーファイルを分けるようなことになるまでは、宣言も定義も同じと考えていいです。
まとめると、メモリ上に変数を保管する場所を確保し、場所に名前をつけた、という状態です。
2行目は1行目で定義した変数aに10という値を代入しています。変数aは初めてここで使うのでこれは初期化作業とも言います。
- 代入
-
数学の代入とは少し違います。2行目の場合はaに10という値を記憶する、という意味になります。ここでつまずくとプログラミングができなくなるので、しっかり抑えてください。
なお、多くの言語で代入は「=」ですが、R言語のように「<-」を用いる言語もあります。
- 初期化
-
初期化、という言葉はかなり多くの人が誤解しています。0を代入することを初期化、と考える人が後を絶ちません。
1行目で変数を宣言し定義しましたが、この状態ではaにどんな値が入っているかは不定です。
2行目のように、プログラマがその変数に何が入っているかわかるようにすることを初期化といいます。
ポインタの話が出てこない限りは、とりあえず定義した後初めて値を代入すれば、初期化している、と思って構いません。
ポインタが絡んだ時のことは、その時にゆっくり解説します。
1行目でメモリーを確保し、その領域にお名前(識別名)をつけて、2行目でその領域に値を書き込んだ、といったほうがわかりやすい・・・のかな?
1行目と2行目をまとめて書いたのが3行目です。4行目のように関数の戻り値を代入することもできます(関数については後述)
変数の型
C/C++言語はとくに型にうるさい言語として知られています。(JavaScriptやperlなど型を明示できない言語もある)。C++なんて型なしではやっていけません。
じゃあその「型」ってなんでしょうか?「型」とはコンパイラに変数をどういう風にメモリー上に配置したらいいのか教えるものです。
| 基本型名 |
整数型/浮動小数点型 |
型の大きさ |
signedの最大値を求めるマクロ |
signedの(実数の)最小値を求めるマクロ |
unsignedの最大値を求めるマクロ |
使用例 |
| void |
不定 |
不定 |
不定 |
存在しない |
存在しない |
ほぼ例外なく関数かポインタとともに用いるので省略 |
| bool型(C99,C++) |
論理型 |
不定 |
存在しない |
存在しない |
存在しない |
bool is_alphabet = true; |
| char |
整数型 |
1byte |
SCHAR_MAX |
SCHAR_MIN |
UCHAR_MAX |
char delim = ','; |
| short(short int) |
整数型 |
不定 |
SHRT_MAX |
SHRT_MIN |
USHRT_MAX |
short rect_x = 320; |
| int |
整数型 |
不定 |
INT_MAX |
INT_MIN |
UINT_MAX |
int a = 3; |
| long(long int) |
整数型 |
不定 |
LONG_MAX |
LONG_MIN |
ULONG_MAX |
long size = 217; |
| long long |
整数型 |
不定 |
LLONG_MAX |
LLONG_MIN |
ULLONG_MAX |
long long size = 217; |
| float |
浮動小数点型 |
不定 |
FLT_MAX |
-FLT_MAX |
そんなものはない |
long long size = 217; |
| double |
浮動小数点型 |
不定 |
DBL_MAX |
-DBL_MAX |
そんなものはない |
long long size = 217; |
FLT_MAXって「魔法科高校の劣等生」の「four leaves technology」みたいでかっこいい!・・・話がそれた。
以上にc言語(c99)の基本型を上げてみた。各型によってメモリー上での大きさ(表せる値の範囲)や表せるものが違う。
INT_MAXとかマクロとかって何?ってなると思うが、そう遠くなくお世話になるだろうから載せておく。解説は後ほど。
ちと難しい話
C言語で型の大きさについての規定はほとんどなく、
- char型は1バイト(8ビットとは言っていない)
- 型の大きさは、short <= int <= long <= long long である。
- int型は -32767~+32767 の範囲が扱える
程度しかない。小数点型に関しては特に規定はないが、事実上IEEE 754に従うので、(今どき従わない非フリースタンディング環境なんてあるのかね?)浮動小数点型についてはIEEE 754を参照すると良い。
まあ、ほとんどcharかdoubleかintしか使わない。ほんと。
コーディングの作法
厳密に型の大きさが定まっている必要が出ることは少なく、boolかcharかdoubleかintしか出番はないはず、それ以外を選択しようとしているなら、本当に必要か考えなおそう。
signedとunsigned
既にちらっと書いてますが、整数型にはsignedとunsignedがあります(浮動小数点型にunsignedはない)。
御存知の通り、PCと言うのはすべてのデータを2進数で表しています。この2進数の一桁をbitと言うわけですが、
1bitを使って正の数か負の数かわかるようにしているのがsigned、すべて正の数とみなすのがunsignedになります。
正の数か負の数かのフラグを使わない分、unsignedの最大値はsignedの最大値のほぼ2倍になります。
例:1byte=8bit,int型の大きさ(sizeof(int))を4byteと仮定すると、
INT_MAX: 2147483647
UINT_MAX: 4294967295
char型以外では、signedやunsignedを省略するとsignedとして扱われます。char型の場合は処理系定義となります(VCのデフォルトはsigned)。
int tmp = 5;
signed int tmp = 5;
unsigned int tmp = 5;
char temp = 6;
signed char temp = 6;
unsigned char temp = 6
1行目と2行目は同値。4行目と5行目が同値である保証はないし、だからといって4行目と6行目が同値である保証もない(処理系定義)
typedef
C/C++にはtypedefという便利な機能があります。さっそく使ってみましょう。
typedef unsigned long DWORD;
typedef DWORD COLORREF;
unsigned long window_head = 0x00FFCCFF;
COLORREF window_head = 0x00FFCCFF;
typedefとは、"すでにある"型に別名をつける機能です。
1行目ではunsigned long型にDWORD型という別名をつけています。
2行目ではDWORD型にCOLORREF型という別名をつけています。
こんな風に別名を付けて何がありがたいかというと、型名を調べるだけでそのデータの格納方法がわかるということです。
3行目では何をしているのかさっぱりですが、4行目を見るとなんか色が関係することをやってるんだな、と察せます。
さらに「COLORREF」でぐぐれば、その詳細もわかります。
https://msdn.microsoft.com/en-us/library/windows/desktop/dd183449%28v=vs.85%29.aspx
When specifying an explicit RGB color, the COLORREF value has the following hexadecimal form:0x00bbggrr
ちなみに1行目と2行目はいずれもWindef.hで定義されているものの引用です。Win32APIに触りたいと思っている方、よく覚えておきましょう。かならすお世話になるでしょう。
コーディングの作法
char型は整数型ですが、主に文字を扱うのに使うことが多い型です。文字以外のデータを扱うのにchar型を使うことは、コードの可読性を下げます。
typedef unsigned char myuint8_t;
typedef signed char myint8_t;
のようにtypedefして使うようにしましょう。
整数リテラル
unsigned int len = 20;
のように、何気なく数値を書いていますが、この数値は「リテラル」と呼ばれます。どう見ても小数ではないのでこれは「整数リテラル」ですね。
なお、浮動小数点リテラルについては
C++11の文法と機能(C++11: Syntax and Feature)
http://ezoeryou.github.io/cpp-book/C++11-Syntax-and-Feature.xhtml#lex.fcon
に投げます。
- 2進数的記法(C++14,VisualStudio2013は未対応,VisualStudio2015は対応)
-
int a = 0b11;// 10進数では、3
int d = 0B1011 ;// 10進数では、11
このように「0b」または「0B」のあとに数字を書きます。
- 8進数的記法
-
int e = 01234;// 10進数では、668
このように「0」のあとに数字を書きます。8進数リテラルは、10進数と区別しにくいので、気をつける必要があります。
- 10進数的記法
int t = 1234;
- 16進数的記法
-
int x = 0x1234 ;// 10進数では、4660
このように「0x」のあとに数字を書きます。
なにが言いたいかというと、うっかりして0から数字を書くなよ!ということです。
const
ある変数をその後で変更する予定がないときはconstをつけるようにするべきです。constは変数を「Read-Only」にします。
const unsigned int len = 20;
len = 21;//エラー
constをつけるときは定義と初期化は同時である必要があります。だって「Read-Only」だもん、後から変更できないんだから初期化も一緒にやらないとダメだよね。
逆に言うと定義と初期化を同時に行うときは殆どの場合constをつけるべき場面です。
注意になりますが、constは「定数」を作るものではありません、あくまで「Read-Only」にするものです。その違いはポインタのところで解説します。
自動変数の生存期間とスコープ
自動変数ってなんなんだってばよっ!となってると思いますが、「いままで出てきたような」変数です。ということはそうでない変数があることくらいは「お察しください」。
スコープとはなにか、については見てもらったほうが速いと思います。
{
int a = 10;
printf("%d\n", a);
}
printf("%d\n", a);//エラー
ずばり{}がスコープです。え?main関数を書いた時に見た?はい、それもスコープです。詳細は関数とはなにかのところで説明します。
スコープの中で確保された変数はスコープの外にでるときに開放されます。消えてなくなるわけです。よって5行目はエラーになります。
printf関数を使うのは初めてなので補足します、とりあえず今はこうすると整数を表示できるんだな、と思っておいてくだい。浮動小数点型だと%dじゃなくて%fだったりlong型だと%ldだったりするわけですが。
C++11の型推論機能
ちょっとC言語を離れてC++を見ていきます。今は型が短いのでいいですが、今に
vector<string>::iterator it;
map<int,list<string>>::iterator i
とか使い出します。こんなに長ったらく書くのはめんdいですし、タイピングミスしやすかったり、コードが見づらくなったりと、3拍子揃って書きたくないです。
そこでauto型の出番です。
unsigned int x = 10;
auto l = x;
とかすると変数lの型はint型になります。便利だね。なお、C++03まではautoは別の意味で使われていたので注意です。
四則演算
やっぱり計算出来ないとプログラミングは始まりません。というわけでまずは四則演算。
int i = 0, delay_time;
//中略
i = i + 1;
double time = 8.5 - 2.1;
double cure = 1.5 * time;
double damage = cure / 10;
unsigned int temp1 = delay_time / 60;
tm_sec += delay_time % 60;
i += 1;
cure -= 10;
i++;
++i;
i--;
--i;
3行目から7行目が四則演算ですね。6行目の割り算は整数精度で行われ、小数点以下は0に近い方向に切り捨てられることを忘れないで下さい。
8行目は割り算の余りを求めるものです。これは整数精度の時のみ使えます。もし浮動小数点型で割り算のあまりを求めたいときは、math.hのfmod関数を使いましょう。
9行目は2行目の略記です。10行目のように引き算などほかの演算記号も同じように使えます。
11行目と12行目はインクリメント演算子、13行目と14行目はデクリメント演算子と呼ばれます。1増やしたり1減らしたりする処理を簡便に書くことができます。
| 演算 | 演算子 | 例 | 意味 |
| インクリメント | ++ | a++ | a に 1 を加える(後置演算) |
| ++a | a に 1 を加える(前置演算) |
| デクリメント | -- | a-- | a から 1 を引く(後置演算) |
| --a | a から 1 を引く(前置演算) |
使用上の注意です。下のコードを見てくだい。
インクリメント・デクリメント演算子は前置と後置で意味が変わるので注意です。私は覚えるのがめんdいので、後置しか使わない派です。
暗黙の型変換とキャスト
ここまでの例ではすべて計算するものの型は揃っていました。では違う場合はどうなるでしょう?
const int a = 10;
const double b = 3;
auto ans = a / b;
int ans2 = ans;
auto ans3 = (int)ans;
変数ansの型はdouble、ansには3.3333333(以下略)が入ります。
一方でans2の型はint、ans2には3が入ります。
また3行目のように型を明示することもできます。これを「キャスト」といいます。ans3の型はint型になります。
- 式の中で行われる変換
-
優先順位の高い型に変換されます。優先順位は
bool < char < short < int < long < long long < float < double
です。
- 代入時の変換
- 左辺の型と右辺の型が異なっている場合は、左辺の型に変換します。
- キャスト時の変換
- 有無をいわさずに指定した型に変換されます。
この法則にしたがって解釈すると、3行目は、aの型はint、bの型はdoubleなのでaがdouble型に変換され(式の中で行われる変換)、double型同士の計算となります。
また4行目は変数ansの型はdoubleですが、左辺のans2の型がintなのでint型に変換されます(代入時の変換)。
このことを利用して割り算の余り(surplus)を求めてみましょう。
const double input = 23;
const int divisor = 7;
const int temp = (int)input / divisor;
const double surplus = input - (divisor * temp);
inputをキャストする必要があるのか?と怒られそうですが、べつに整数精度の結果で事足るのでキャストしました。
よくキャストを「ある型とみなす」と説明する人が居ますが、誤りです。bitの並びが変わることもあることからわかるように、実際に変換されます。
コーディングの作法
C言語のキャストは、非常に強力で、どんな型にでも変換ができます。ゆえにしてはいけない型変換もできてしまいます。
そこでC++ではキャストが4種類にわかれました。
| 名称 | 説明 | 使用 |
|---|
| dynamic_cast | 基本クラスから派生クラスへのキャスト | 使用するべきではない |
| const_cast | const を外すキャスト | 使用するべきではない |
| static_cast | double から int など暗黙の変換のあるキャスト | 使用可 |
| reinterpret_cast | double * から long long などの無理やりキャスト | なるべく使用しない |
詳細な説明は
キャスト | プログラマーズ雑記帳
http://yohshiy.blog.fc2.com/blog-category-9.html
に譲りますが、Cのキャストは理由がない限り使わず、C++のstatic_castを使用しましょう。
const int temp = static_cast<int>(input) / divisor;
もっとも、まともなコーディングをしていれば、malloc,calloc,realloc関数以外でキャストを使う場面はないはずです。
もしあなたがキャストを使おうとしているならば、それはあなたが寝ぼけているのか、ライブラリ作者がうっかりしている、ということになります。
後者なら、作者に文句を言いましょう。(実際私はDxLibraryの作者に色の扱いについて文句を言って、Ver 3.13eで修正してもらいました)
signedとunsignedの変換はとくに理由のない限りしないようにしましょう。
promotionsとconversions
型変換、と一口に言っても2つあり、promotionsとconversionsとそれぞれ呼ばれます。
promotionsがなにか、については
C++11の文法と機能(C++11: Syntax and Feature)
http://ezoeryou.github.io/cpp-book/C++11-Syntax-and-Feature.xhtml#conv.prom
に丸投げするとして、promotionsでなければconversionsである(そりゃそーだ)。
conversionsは一般に危険をはらんでいます。何故かというと、変換元の数値を変換先の型で表せないかもしれないからです。
unsigned charが8ビット、unsigned intが16ビットと仮定して実例を上げてみましょう。
int main(void){
unsigned int ui = 1234 ;
unsigned char uc = ui ; // 210
}
この場合、unsigned int型は、16ビット、uiの値は、2進数で表すと0000010011010010になります。unsigned char型は8ビット。つまり、この場合の対応する下位桁の値は、2進数で11010010(uiの下位8ビット)です。よって、ucは、10進数で210となります。
しかし、そもそも型変換でオーバーフローやアンダーフローを起こさないようにコーディングするべきでしょう。
stdint.h/cstdint
先ほど「文字以外の目的でchar型を使うときはtypedefして使うようにしましょう」と言いましたが、毎回typedefするのはめんdいです。
また、先程から散々言ってるように、C/C++では型の大きさについて、明確な規定はほぼありません。これでは厳密に何bitかを使いたいとき(HTTP通信など)に困ってしまいます。
そこでstdint.h/cstdintの出番です。これはC99/C++11で追加された標準ライブラリで、主に以下の型が使えます。
int8_t, uint8_t, int16_t, uint16_t, int32_t, uint32_t, int64_t, uint64_t
これらは厳密に型の大きさが決まっています。(ゆえにすべての処理系で実装されているわけではない)
uint8_t color_r = 187;
int64_t receive_timestamp;// 受信タイムスタンプ
//中略
int64_t sum = sum1 + sum2;
よく使うのはこの2つかな?あるって知ってると何かと便利。
ビット演算
ビッド演算とは、各bitに対して論理演算を行うことを指します。なお、特にシフト演算では、変数はunsigned、または正の整数である必要があります。負の数の場合動作は実装定義となります。
まあ、そもそもsignedな整数にビット演算をするべきではありません。
左シフト
uint32_t si_a = 5;//101
const uint32_t si_b = 4;
const uint32_t re_si = si_a << si_b;//80:1010000
1つ左シフトするごとに、2をかけているのと同じ効果が得られる。この場合は24 = 16倍していることになる。
かならず以下の点をコーディング時に確認して行うこと。
右シフト
uint32_t si_a = 37;//100101
const uint32_t si_b = 4;
const uint32_t re_si = si_a >> si_b;//2:10
左シフトと逆の効果が得られる。
かならず以下の点をコーディング時に確認して行うこと。
ビットの論理積
const uint32_t a = 0b10110;//22
const uint32_t b = 0b11010;//26
const uint32_t re = a & b;//18:0b10010
各bitにAND演算をします。

結果はこの表に従います。
ビットの論理和
const uint32_t a = 0b10110;//22
const uint32_t b = 0b11010;//26
const uint32_t re = a | b;//30:0b11110
各bitにOR演算をします。

結果はこの表に従います。
ビットの排他論理和
const uint32_t a = 0b10110;//22
const uint32_t b = 0b11010;//26
const uint32_t re = a ^ b;//12:0b1100
各bitにXOR演算をします。

結果はこの表に従います。
ビットの反転
const uint8_t a = 0b10110;//22
const uint8_t re = ~a;//233:0b11101001
各ビットにNOT演算をします。1の補数をとる、ともいいます。
関数とは
既にそこかしこで出てますが、改めて。関数とは、処理の集合です。C/C++では、すべてのプログラムは必ず1つ以上の関数が含まれています。
これまで見てきたmain関数も関数の一つです。C言語においてとにかく大事なものです。そのくせ独習Cの説明は十分とは言えません、あれで説明してるつもりなんですかね。
関数の一般的な書き方は
[戻り値の型] ([関数呼び出し規約]) [関数名](仮引数リスト){
//処理
}
です。戻り値の型がvoid以外の時は、必ず戻り値を返さなければなりません。
//これは誤り
int do_something(void){
//do something
}
//これは正しい
int do_something2(void){
//do something
return 0;
}
関数の呼び出し規約は省略することが多いが(その場合__cdeclになる)、Win32APIを使うならお世話になるだろう。後述する。
実際に関数を作るときには「プロトタイプ宣言」という物を書くことになる。書き方を立方体の体積を求める関数を例に説明する。
2行目が関数のプロトタイプ宣言と呼ばれるものだ。戻り値の型、(呼び出し規約)、関数名、仮引数リストを書く。
なお、その関数を使用するまでに関数が宣言されている必要があるため、原則として#define文やtypedefや定数宣言のあとにまとめて書いておくこと。
このcalc_volume関数が定義されるのは、10~13行目の部分だ。ここで関数の実際の処理を書く。
この関数が呼び出される7行目だ。ここで初めて実際に定義に基づいて処理を行う。calc_volume関数内のreturn文にかいたものが変数resultに代入されている。
C標準ライブラリ
C標準ライブラリとは、プログラマーがよく使う機能をひとまとめにしてC言語自体が提供している関数群のことです。
代表的なものとしては、puts, getcahr, fgets, time, clock, printf, sprintf, scanf, strcomp, memcpy, malloc, callocなどの関数でしょうか。
これらはいくつかのヘッダーファイルをincludeすることで使えます。
例えば、printf関数はstdio.h, calloc関数はstdlib.h, clock関数はtime.hをincludeすることで使えます。
includeし忘れると、コンパイラーに「そんな関数知らねーよ」と怒られます。
ここで改めてはじめて書いたコードを見て欲しい。
puts関数が出てくると思う。これはどういう関数なのだろうか?この関数はC標準ライブラリの関数なので関数名でググってみょう。大概は「関数名 MSDN」で適当な情報がでる。
https://msdn.microsoft.com/ja-jp/library/tf52y4t1.aspx
以下の様な点に着目して見るといい。
関数の型
宣言、とか定義とかさっきから言ってるところからもう察しているかも知れませんが、関数も変数と同じくオブジェクトなので、メモリー上に実体があり、型も存在します。
「型」がなにかについては変数のところで説明しましたが、「型」とはコンパイラにオブジェクトをどういう風にメモリー上に配置したらいいのか教えるものなのでした。
関数になってもなにも変わりません。コンパイラーに
を教えます。だからcalc_volume関数の型は、「double(double, double, double)」型です。これが分かれば、コンパイラは関数を呼び出すアセンブリコードを書いてくれます。
このことは関数ポインタのところで大事になるので、覚えておいてくだい。
関数を作って使ってみよう
細かい理屈はひとまず置いておいて、まあ関数を作ってみましょう。オーバーフロー対策はif文を教えてないのでまだいいです。
練習問題
-
main関数の他に以下の機能を持つ関数を書き、main関数から呼び出せ。
- 機能
- puts関数を呼び出し、「関数arikitari_na_kannsuuが実行されました」と表示する
- プロトタイプ
void arikitari_na_kannsuu(void);
-
以下の機能を持つ関数を作成し、main関数から呼び出し、戻り値をpriintf関数で表示せよ。
- 機能
- 2つの引数を受け取り、その和を返す。
- プロトタイプ
uint64_t add(uint64_t a, uint64_t b);
- ヒント
-
main関数側はこう書けばいい。
printf("%ld", add(7, 2));
当たり前だが、stdint.hをincludeしなければならない。
-
以下の機能を持つ関数を作成し、main関数から呼び出し、戻り値をpriintf関数で表示せよ。
- 機能
- COLORREF型の引数を受け取り、G(緑色)の値を返す。
- プロトタイプ
uint8_t myGetGValue(COLORREF color);
- ヒント
-
COLORREF型を使うにはwindows.hを一番先にincludeする必要がある。
main関数側はこう書けばいい。
COLORREF color = RGB(137, 195, 235);//RGBマクロでCOLORREF型の値を作製
printf("%d", myGetRValue(color));
当たり前だが、stdint.hをincludeしなければならない。
内部の演算は右シフトとAND演算をすれば求められるはず。
COLORREF型については既に説明した。windows.hをincludeすればあそこで書いたtypedefが既にされている。
マクロ GetGValue を用いてはならない。
スタック領域
Cで扱うメモリ領域は一般に、プログラム領域、静的領域、スタック領域、ヒープ領域の 4つに大別されます。
main関数が呼び出される時にある程度広い範囲のメモリーを確保します。この領域をスタック領域、といいます。
変数をメモリー上に確保して~とか、関数はメモリー上に実体があり~とか言ってましたが、ここのことです。
自動変数(これまで見てきた変数)や関数の引数、戻り値、リターンアドレスなどはここに記録されます。
ではどういう風に記録されていくのでしょうか?
- main関数が呼ばれるとき、スタック領域を確保する
- 引数を後ろから順に書き込む
- 復帰情報(リターンアドレスなど)を書き込む
- 関数の処理が始まって、変数が確保されたりする
わかりにくいので図で説明します。
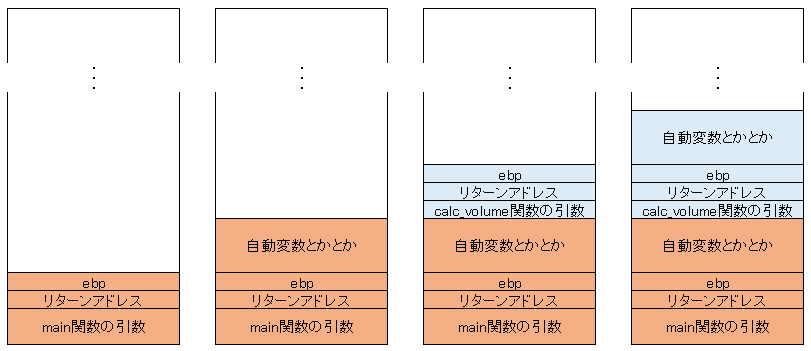
プログラムが呼ばれると(特に定めない限り)main関数が呼ばれます。この時スタック領域が確保されるわけです。そのあとにmain関数の引数やら戻り値の領域やらリターンアドレスが書き込まれます。(図の一番左)
何が言いたかったか、ですが、単純。関数も変数となんら変わりません!・・・てことです。いやね、これがわからんと関数ポインタが説明できんのよ。
main関数の引数って何?
先ほどさらっと「引数」という言葉を使いましたが、解説がまだでした。実例を見て行きましょう。
さて疑問が噴出していることと思いますが気にすることはありません。[i]とかifとかforとかはちゃんと後で説明します。これをコンパイルしてできた002_show_argv.exeを
002_show_argv.exe arikitari na world!
のように実行してみてください。すると
argv[0]:[任意の場所]\002_show_argv.exe
argv[1]:arikitari
argv[2]:na
argv[3]:world!
のようになったと思います。こんな感じでexeはコマンドライン引数を受け取れるんだなぁと思っていてください。
これを使ってプログラムにいろいろな値を与えられるわけです。
main関数の戻り値の意味
最初の方でも書きましたが、main関数はint型で、必ず値を返さなければなりません。
今までのサンプルコードを見てきた人は、「main関数は必ず0を返さなければいけないんですか?」と思ったのではないでしょうか?(むしろ思っててほしいです)
いいえ、そんなことはありません、下のサンプルを見てください。
#include<stdio.h>
#include<stdlib.h>
#include<limits.h>//in gcc
#include<errno.h>//in gcc
#ifndef _cplusplus
#define nullptr NULL
#endif
int get_integer_num(const int max, const int min){
//機能:標準入力を数字に変換する。
//引数:戻り値の最大値,戻り値の最小値
//戻り値:入力した数字、エラー時は-1,EOFのときはEOF
char s[100];
char *endptr;
if (nullptr == fgets(s, 100, stdin)){
return INT_MIN;
}
if ('\n' == s[0]) return INT_MIN;
errno = 0;
const long t = strtol(s, &endptr, 10);
if (0 != errno || '\n' != *endptr || t < min || max < t)
return INT_MIN;
return (int)t;
}
int main(void){
printf("今の時間帯は?\n1.朝 2.昼 3.夜(まだ寝ない) 4.夜(もう寝る)\n");
const int time = get_integer_num(4, 1);
switch (time){
case 1:
printf("おはようございます\n");
break;
case 2:
printf("こんにちは\n");
break;
case 3:
printf("こんばんは\n");
break;
case 4:
printf("おやすみなさい\n");
break;
default:
time = -1;
break;
}
return time;
}
このサンプルコードでは、時間帯を聞いたところで入力された値が返されるようになっています。
「上のint get_integer_numは何?」って?後で説明するのでここではスルーしてください。
このように、main関数では必ずしも0を返す必要はありません。この程度のコードなら普通に0返せばいいじゃんと思うかもしれませんが、そんなのは今回どうでもいい話です。
問題なのはmain関数は0以外の値を返しても大丈夫かどうかなので。
じゃあメイン関数の戻り値にはどういう意味があるのかって?そのプログラムの内部においては何にも関係ありません。この値はプログラムの外部に影響があります。
我々が作ったプログラムはどうやって呼ばれるかというと、別の何らかのプログラムが呼び出しています。普通の関数がそうであるように、main関数も例外ではなく、呼び出し元に値を返します。
この値をどう処理するかは各OSによって異なり、さらにバッチファイルなどから呼び出す場合はその値に対する挙動はプログラマーが決められます。
細かいことはどうでもいいです。とりあえずここでは、main関数内の値はプログラム内部には影響がないってことだけ覚えておいてください。
ソースファイルを分ける
一つのファイルですべてのソースコードを書くと、コンパイル時間が増加する要因となり、また見通しの悪いプログラムになりやすい(はい、私です。いっつもファイルを分けるのをめんdいからやらないのは)です。
先に、プロトタイプ宣言はソースコードの冒頭に、と言いましたが、この内外部公開するものはヘッダーファイルに書きます。この他にヘッダーファイルに書くものとしては、共通してincludeするファイルや、公開する構造体定義や列挙型定義などです。
通常変数やinline関数のプロトタイプ宣言を書くのはいろいろ面倒なので(externすればいいが)、あまりしません。とくに変数を共有しなければならないことは極めて稀だと思います。
例を見ましょう。
#ifndef INC_ARIKITARI_H
#define INC_ARIKITARI_H
#if (defined(_MSC_VER) && _MSC_VER > 1000) || defined (__GNUC__) && (__GNUC__ >= 4 || (__GNUC__ == 3 && __GNUC_MINOR__ >= 4))
#pragma once
#endif
int get_integer_num(const int max, const int min);
#endif INC_ARIKITARI_H
#include "arikitari.h"
#include<stdio.h>
#include<stdlib.h>
#include<limits.h>//in gcc
#include<errno.h>//in gcc
int get_integer_num(const int max, const int min){
//中略
}
#include "arikitari.h"
#include<stdio.h>
#include<limits.h>
int main(void){
const int input = get_integer_num(INT_MAX, INT_MIN);
printf("input=%d", input);
return 0;
}
ヘッダーファイルは必ず関数定義があるファイルと関数使用箇所両方でincludeするようにします。また、ヘッダーファイルの名前は普通関数定義があるファイル名と同じにします。
何度も言いますが、すべての関数を公開する、ヘッダーファイルで宣言する必要はありません。あくまで他のファイルからも使いたい関数等を公開するわけです。
#if (defined(_MSC_VER) && _MSC_VER > 1000) || defined (__GNUC__) && (__GNUC__ >= 4 || (__GNUC__ == 3 && __GNUC_MINOR__ >= 4))
は、#pragma onceに対応していないコンパイラー(というよりプリプロセッサか)に対応するものです。詳細はプリプロセッサの項目で。
bool型と_BOOL型とBOOL型と
C++では当初から真と偽を表すbool型が導入され、C言語でもC99でbool型が使えるようになりました。
C99のbool型は_BOOL型をマクロを使って実装しています(マクロが何かは後ほど)。
実際に使い方を見ましょう。C++ではstdbool.hのincludeは不要です(無理にincludeしても勝手にincldueを外されます)。
#include <stdbool.h>
int main(void){
//前略
bool no_first_skip = true;
bool no_dct_decimate = false;
//後略
return 0;
}
C99/C++のbool型は、真と偽はtrueとfalseに対応し、int型に変換すると1と0になります。それ以外の値を入れられることは保証されていません。
さて、ここまでならなんら問題はなかったのですが、問題はBOOL型です。ここでいうBOOL型はWin32APIのBOOL型です。
Win32APIのBOOL型は何をキチがえたのか、平気で負の値とかが入っていたりします。それもそのはず、ただ単にint型をtypedefしてBOOL型を作っているからです。
これにはC言語が真と偽を非0と0に対応づけてきた歴史も関わってきます。
なにが言いたいかというと、false(FALSE)が0であることは保証されているが、true(TRUE)が1であることは保証されない、ということです。
うっかりすると足を救われるので注意です。
条件文とループ
条件文
前にbit演算のところでAND演算とかOR演算とかやったと思いますが、それをbit単位でなく、変数単位でやるのが条件文です。
条件文の演算結果は事実上bool型になります。つまり、真と偽は、1と0に対応します。例を見てみましょう。
int a = 10;
int tmp = (5 == a);//0になる
条件文は多くの場合大小比較や同値比較と同時に用いられるので、その演算子をまとめておきましょう。
| 演算子 |
意味 |
| == |
等しい |
| != |
等しくない |
| <= |
(左は)(右)以下である |
| >= |
(右は)(左)以下である |
| < |
(左は)(右)より小さい |
| > |
(左は)(右)より大きい |
これに加えてAND,OR,NOT演算子があります
| 演算子 |
意味 |
| && |
かつ(AND) |
| || |
または(OR) |
| ! |
否定(NOT) |
if文
条件式をそれ単体で使うことは、そこまで多くなく、if文やこの後紹介するwhile,for,do-while文と共に用いられます。
if文はプログラムを組む上で無くてはならないものです。例を見てみましょう。
if(条件式)
//条件式が真の時
else
//条件式が偽の時
この書き方だと処理が一行しか書けません。複数行書くときは{}を使います。
気をつけて欲しいのですが、{}がなくともスコープがあります。ところで言うまでもないですが、else節はなくても構いません。
int first_number, second_number, third_number, max_number, center_number, min_number;
//3つの変数になにか値を代入
if (first_number > second_number){//1番目の数と2番めの数を比較
max_number = first_number;
center_number = second_number;
}
else{
max_number = second_number;
center_number = first_number;
}
if (third_number > max_number){//3番めの数と上で出した「1番目の数と2番めの数」の大きい方と比較
min_number = center_number;
center_number = max_number;
max_number = third_number;
}
else if(third_number > center_number){//3番めの数と上で出した「1番目の数と2番めの数」の小さい方と比較
min_number = center_number;
center_number = third_number;
}
else{//3番目の数が最小の時
min_number = third_number;
}
このようにif文 else if のように連ねて書くことも可能です。
if(5 == a)
int x = 7;
else
x = 6;//これはだめ
そもそもif文の中で変数を宣言しないようにしましょう。変数を宣言したい、そう思ったら、直ちにその部分を関数化しましょう。
コーディングの作法
if文では、else節に正常な動作を書くと、多くの場合ですっきり書けます。
if(条件文){
//エラー処理
}
else{
//正常動作
}
大切なのが、正常な動作の時の流れがもっとも簡潔であるように書くことです。
また、条件式を書く上での注意ですが、同値比較(==)は「=」が2つですが、ついうっかり1つにしてしまいがちです。そこで、このように書くようにしましょう
if(5 == a)//正しい書き方
if(a == 5)//これも正しい書き方だが、推奨しない、ミスの元
if(5 = a)//これはコンパイルエラー
if(a = 5)//これはコンパイルエラーにならない、aに代入した後のaが0か否かが判別される
constがついた変数や、数値、マクロで定義された値を左側、変数を右側に持っていくようにします。
こうすることで、書き間違えた時にコンパイルエラーになります。(変更不可能なものに代入しようとしています、など)
エラー処理等、明確に実行文が1行しかない、と言える時を除き、原則{}はつけましょう。あとで文が増えた時に付け忘れるのを防ぐことができます。
3項演算子
if文とは一味ちがう書き方です。見てみましょう。
const int hoge = 17;
const int isEven = (hoge % 2)? 1324 : 2432;
const int hoge = 17;
int isEven;
if(hoge % 2){
isEven = 1324;
}
else{
isEven = 2432;
}
if文を使って書くより簡単ですし(スコープの問題がない)、代入する変数にconstが付けられます(ワタシ的にはここが美味しい)
この書きかたですが、「一行で」かけるので、後に説明するプリプロセッサマクロでしばしば用いられます。
・・・って私は教わったんだけど、マクロにして使ったことってないなぁ。それくらいならinline関数(C++の機能)にしちゃうし。
switch文
if文が高級な条件分岐文とするならば、switch文は低級な条件分岐文といえますが、最大のメリットは、一度の条件式で複数の分岐が作れることです。
char time_when;
//do something
switch (time_when)
{
case 'a':
puts("朝");
break;
case 'b':
puts("昼");
break;
case 'c':
puts("夜");
break;
default:
break;
}
switch文には必ず「default:」を書きましょう。
「case 'c':」とかは「ラベル」といいます。後述するgoto文にも登場するので頭の片隅においておいてください。
「break;」はswitch文を抜け出すために用います。もし、6行目の「break;」がなかった場合、5行目を実行した後8行目を実行します。つまり必ずしもbreakは必須ではありません。
switch文を「低級な条件分岐文」と表現したのは、アセンブリコードのjmp命令にそっくりの構文だからです。
このjmp命令にそっくりという性質を活かして
send(register short *to, register short *from, register count)
{
register n = (count + 7) / 8;
switch(count % 8) {
case 0: do { *to = *from++;
case 7: *to = *from++;
case 6: *to = *from++;
case 5: *to = *from++;
case 4: *to = *from++;
case 3: *to = *from++;
case 2: *to = *from++;
case 1: *to = *from++;
} while(--n > 0);
}
}
なんていう、わけわかめなプログラム(Duff's deviceというプログラム高速化のための最適化技法)を書いた人が居ますが、やめましょう。
このswitch文、あとで出てくる列挙型(enum)とものすごく相性がいいです。#defineをわんさか書こうとしているそこのアナタ、enumを使いましょう。
while文
プログラミング言語へのループ文の導入は画期的なものでした。while文はC言語におけるもっとも簡単なループ文です。
while(継続条件) 実行文;
if文と同様、実行文は{}を使って複数行書くことができます。例を見てみましょう。
while('\n' != getchar());
for文
はっきり言って、for文のほうがwhile文より使いやすいです。そしてfor文はこのあと説明する配列と殆どの場合一緒に使います。
for(初期化文; 継続条件; カウンター等実行文);
for(unsigned int i = 0, sum = 0; i < 10; i++) sum += i;
こんな感じ。まあそのうち呼吸をするがごとく登場するので、これ以上は例を上げないでおきます。実用的な例を上げたほうが良いもんね、やっぱり。
do-while文
事後評価文とでも言えばいいのでしょうか。whileと違い、一度実行し、それからループするかを判断します。
do{
//実行文
}while(継続条件)
これまた多くの場合、ポインターや標準入力とともに使うので実例はその時に。
プリプロセッサー
お待たせしました。ようやくプリプロセッサーのお話です。
はい、#includeとかなにげに書いてきたものが何なのかわかります。
- #include
- #define
- #if/#else
- #ifdef/#ifndef
- #error
- #warning
-
#pragma
- #pragma once
- #pragma comment
- #pragma ident
これだけ種類が有ります。解説するのは#includeと#define、#pragma once、#pragma commentにとどめます。他は
http://itref.fc2web.com/c/preprocessor.html
を参照してください。なお、#if/#else/#ifdef/#ifndefはこれまでもこれからもしれっと使います。
#include
.cとか.cppが読み込めないわけではないのですが、ほぼ100%ヘッダーファイルを読み込むのに使います。
#include "DxLib.h"
#include <stdio.h>
一般的なお話として、<>で囲むとコンパイラーの規定の場所とコンパイルオプションで指定した(gccなら-Iオプション)場所からヘッダーファイルを探します。
また、""で囲むと、それに加えて、#includeを書いたファイルと同じ場所も捜索対象になります。
ゆえに自分で作ったヘッダーは""で囲い、C/C++標準ライブラリ―のヘッダーは<>で囲むのが普通です。ありきたり。
#define
しばしば、const, enumと並んで定数を作る、と言われますが、残念ながらいずれも定数ではありません。
#defineはコンパイル前にソースコードを置換するものです。で、「マクロ」と呼ばれます。Excelとかのマクロとはちと違うので注意です。
#define WINDOW_HEIGH 1024
こんな風に定数っぽいのを作ることもできますし
#define MAX(A, B) (A > B)? A : B
みたいに関数もどきも作れます。・・・がしかし、使いません。だってそれぞれ
static const int WINDOW_HEIGH = 1024;
template<typename T_>
inline T_ max(T_ a, T_ b){
return (a > b)? a : b;
}
のほうがわかりやすいじゃん。で、マクロを何に使うかというと、コンパイラー間の差異を吸収するために使います。どういうことでしょうか?
最初に話したとおり、コンパイラーには何種類か有りますが、その中でも人口が多いVisual Studio C Compiler(以降VC)とGNU C Compiler(以降gcc)の2つだけ見ても、その差異は大きいです。
例えばfloat型とdouble型の計算速度のところで出したサンプルコードを見てみましょう。
#ifndef __GNUC__
#pragma comment(lib, "setupapi.lib")
#pragma comment(lib, "hid.lib")
#pragma comment(lib, "winmm.lib")
#endif
ifndefというのはそのマクロ(この場合__GNUC__)が既に定義されているかを(プリプロセッサが)調べ、真なら対応するendifまでを有効にするものですが(偽ならその部分はコンパイラーに渡されない)
あとで説明する通りgccは「#pragma comment」という書き方はできません。この場合だとコンパイルオプションに
-lsetupapi -lhid -lwinmm
つけるわけですが・・・ってそんな話はよくって、対応してない機能をコンパイラーに渡すと当然コンパイルエラーになるのでこのようにgccコンパイラーでコンパイルする時を考えてこのように書いています。
すでに察しているかもしれませんが何も書かなくてもいくつかのマクロがdefineされています。例えばVCなら_MSC_VER、gccなら__GNUC__,__GNUC_MINOR__などがその代表的なものになります。
#if (defined(_MSC_VER) && _MSC_VER > 1000) || defined (__GNUC__) && (__GNUC__ >= 4 || (__GNUC__ == 3 && __GNUC_MINOR__ >= 4))
#pragma once
#endif
ヘッダーファイルに分ける、のところで書いたこの文の意味も今なら分かるでしょう。
#pragma onceという書き方に対応したのがVisual Studio.NET 2003以降、gcc3.4以降だからです。
#pragma comment
なんかすでに使っているので解説が必要か疑問ですが、.libファイルや.aファイルをリンカーにくっつけて、とお願いするために使います。ただし先述の通りVCやclang,bcc等限定の機能になります。
なのでgccでコンパイルする予定があるなら(常にその可能性を想定するべきですが)さっきのような対策が必要です。
#pragma onceとインクルードガード
その昔#pragma onceが使えなかった頃、ヘッダーファイルが複数読み込まれると、2重定義です、と言われコンパイルエラーになりました。この対策として
#ifndef _INC_STDIO
#define_INC_STDIO
//ヘッダーファイルの中身を書く
#endif /* _INC_STDIO */
といったことをしていました。こういう書き方をインクルードガードといいます。でもこんなの書くのはめんdいですよね?そこで生まれたのが#pragma onceです。
ヘッダーファイルの冒頭に
#pragma once
と書くだけです。
ただし、普通は#defineを使ったインクルードガードと併用します。その理由は実際に使っていれば分かるはず。複数のヘッダーで同じことを書かないといけない時にこれがあると便利なんです。
#pragma warning
実例を見たほうが早いでしょう。プログラムはAviUtlプラグインで有名な透過性ロゴフィルター(makki氏)のSIMD化版(rigaya氏)の一部です。
#pragma warning (push)
#pragma warning (disable: 4244) //C4244: '=' : 'int' から 'short' への変換です。データが失われる可能性があります。
static BOOL create_adj_exdata(FILTER *fp, LOGO_HEADER *adjdata, const LOGO_HEADER *data)
{
int i, j;
if (data == NULL)
return FALSE;
// ロゴ名コピー
memcpy(adjdata->name, data->name, LOGO_MAX_NAME);
// 左上座標設定(位置調整後)
adjdata->x = data->x + (int)(fp->track[LOGO_X]-LOGO_XY_MIN)/4 + LOGO_XY_MIN/4;
adjdata->y = data->y + (int)(fp->track[LOGO_Y]-LOGO_XY_MIN)/4 + LOGO_XY_MIN/4;
//中略
return TRUE;
}
#pragma warning (pop)
このプログラムでは11,12行目がint型からshorに暗黙の型変換を行おうとしているのでコンパイル警告が出ます。
もしshort型で表せない大きさのデータだったら正常に変換できないのでこの警告はもっともな話です。むしろ警告してくれてありがとうです。
しかし、作者曰くこの場合はそうはならないらしいです。だとすればその警告は目障りです。なのでこのように#pragma warningを使って警告を消しています。
ただしプログラム全体でその警告が消えると不都合なので、この関数だけ警告が消えるように#pragma warning (push)/(pop)しています。
ただしこの書き方はVCの書き方でgccだとまた書き方が違います。
VCだと警告番号ですがgccやclangだと警告の種類を指定するようです。
warning | MSDN
https://msdn.microsoft.com/ja-jp/library/2c8f766e.aspx
Diagnostic Pragmas - Using the GNU Compiler Collection (GCC)
https://gcc.gnu.org/onlinedocs/gcc/Diagnostic-Pragmas.html
controlling diagnostics via pragmas | clang 3.7 documentation
http://clang.llvm.org/docs/UsersManual.html#controlling-diagnostics-via-pragmas
#pragma warning (push)
#pragma warning (disable: [警告番号])
//警告を無効にする部分のコード
#pragma warning (pop)
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "[警告の種類]"
//警告を無効にする部分のコード
#pragma GCC diagnostic pop
#pragma clang diagnostic push
#pragma clang diagnostic ignored "[警告の種類]"
//警告を無効にする部分のコード
#pragma clang diagnostic pop
大事なことを言います。本来警告が出たら出ないようなコードを書くべきなのです。このように警告を消したり、キャストして警告を消すのはやってはいけません。
なんどでもいいますが、本来は「警告を出していただき、コンパイラー様、ありがとうございます」なのです。
明確に問題ない、と言える警告を除き、警告を消すことのないようにしましょう。
標準出力(stdout)
すでにputs関数やprintf関数を何気なく使っていますが、標準出力について説明していませんでした。
標準出力とは、プログラムが書き出すデータのストリームのことで、とくに指定しない限りコンソール画面に出力されます。
と、書けば察しがつくと思いますが、標準出力は変えられます。リダイレクトでググってください。
それ故、puts, printf関数などは「コンソール画面に文字を表示する関数」としばしば誤解されます。
なお、stdoutとはSTanDard OUTputの略です。C++は違いますが、他の言語でもこの言葉が使われることがおおいです。
よく使う標準出力関係の関数
int puts(const char *str );
int printf(const char *format [,argument]...);
int fprintf(FILE *stream, const char *format [,argument ]...);
int fputc(int c, FILE *stream);
int putchar(int c );
C言語の標準出力関数、とくにprintf関数はとても優秀で、正直C++の出力方法よりよほど使いやすいです。ちなみにC++では
std::cout << "arikitari na world!" << std::endl;
のようにします・・・が、はっきり言って使いにくいです。C++はたしかに使いやすいですが、標準出力の使いにくさだけはいただけません。
標準エラー出力(stderr)
はっきりいって出番は少ないです。が、標準出力をたとえばファイルにリダイレクトした時、エラーはコンソールに出す、みたいなときには便利ですし、習慣的にエラーは標準エラー出力に出力することになっています。
よく使う標準出力関係の関数
int fprintf(FILE *stream, const char *format [,argument ]...);
標準入力(stdin)
C言語の標準入力ははっきり言ってクソです。どれくらいクソかというと、標準ライブラリーにまともに数値を受ける関数がありません。
数値入力を受けたいだけなのに一度文字列として受け取りそれを数値に変換する処理を自前で書かないといけないなんてアホでしょ。
また、入力ストリームへの攻撃対策が弱かったり、しばしば改行文字を入力ストリームに置き去りにしたりと、文字すら安全に読み込むのは難しいのです。
その代表格がgets関数です。文字列を受け取る関数なのですが、あまりの危険性から、C99では非推奨、そしてついにC11では使用禁止になりました。
この背景には、後述しますがC言語にはそもそも「文字列」という概念がない、ということがあります。文字の実態はただの数字で、文字列はその集合でしかないのです。
そんなC言語でどうにかこうにか安全に標準入力を扱おう、というのが今回の目標です。
まさかの愚痴スタートです、すみませんでした。標準入力とは、プログラムに入ってくるテキストデータのストリームです。
殆どの場合、キーボードから文字入力を受けます。言語を問わず数値入力を受けるためには一度文字列として読み込み、数値に変換する、という作業を行いますが、他の言語ではその作業を意識することはありません。
先程から、C言語の標準入力は糞だ、と言っていますが、少なくとも文字列の入力を受けることに関しては改善されてきています。
MSVCではVisual Studio 2005の頃から、C標準ライブラリーを置き換える関数群を提供しています。scanf_sなどのように末尾に「_s」が付きます。
またC11でこれに追従する(というよりほぼパクリ・・・)ように同名の関数を提供しています。これはgcc4.9.1くらいからつかえます。
まあ、実例を見て行きましょうか。
2通り目と3通り目の文字列読み込みでは、文字入力で大概の参考書で真っ先に使うscanf関数を紹介しましたが、個人的にはscanf関数は使いにくいなぁという印象です。
私はfgetsで改行文字ごと読み込んで改行文字をNULL文字に置き換えるほうが好きです。理屈が単純ということはそれだけバグを減らせるので。
もちろんscanfにはそれなりの良さがあるわけですが、だとしても3番目のように一度読み込んでからsscanfしますね。
get_integer_num関数については簡単に説明すると、まず、fgets関数で文字列を受け、文字列をstrtol関数で数値に変換しています。
というわけでポインターと文字列について何一つ説明していないのにばんばん使っていますが、すみません。すぐに解説します。
練習問題
以下のソースコードは標準入力から数値を受け取り、指定範囲内でない数値に対しては再度入力を促すプログラムである。
しかし、これは意図した動作をしない。問題点を可能な限り多くあげよ(getnum関数はget_integer_num関数のもとになった関数でエラー対策に難がありますが、そこはスルーしてください)
#include<stdio.h>
#include<stdlib.h>
int getnum(void){
char s[100];
long t;
char *endptr;
fgets(s, 100, stdin);
errno = 0;
t = strtol(s, &endptr, 10);
if (errno != 0 || *endptr != '\n' || (t < INT_MIN || INT_MAX < t))
return -1;
return t;
}
int getnum_customized(const int max, const int min){
if (max < min) return -1;
int flag0;
do{
flag0 = getnum();
if (flag0 < min || flag0 > max)
system("cls");
printf("再入力してください。\n");
} while (flag0 < min || flag0 > max + 1);
return flag0;
}
int main(void){
printf("値を入力してください。\n");
const int flag = getnum_customized(100, 0);
printf("取得した値は%dです。\n", flag);
return 0;
}
回答
-
19-21行目は19行目の時の条件を満たした場合に20,21行目を実行することを意図していると思われるが、この書き方では21行目は条件判定にかかわらず実行される。
if (flag0 < min || flag0 > max){
system("cls");
printf("再入力してください。\n");
}
が正しい。前に「エラー処理等、明確に実行文が1行しかない、と言える時を除き、原則{}はつけましょう。」と言った理由はこれ。もともと20行目はなく、このコードを書いた人曰く後から追加したらしい。
-
19行目と22行目に注目すると、条件判定がおかしいことに気がつく。つまり、先の修正を踏まえると、flag0がmaxと同値の時、再入力を求める文章が出るのにもかかわらず、実際には再入力することなdo-while文を抜けてしまう。
-
18行目に注目すると、getnum関数の戻り値チェックをしていないことに気がつく。このgetnum関数は11行目にあるようにエラー時は-1を返すので、その判定をする必要がある。つまり
if (-1 == flag0 || flag0 < min || flag0 > max){
とするべきである。
これらを踏まえ、また無駄な条件判定を減らし、getnum関数を上に上げたget_integer_num関数に置き換えると
#include<stdio.h>
#include<stdlib.h>
#include<limits.h>//in gcc
#include<errno.h>//in gcc
#ifndef _cplusplus
#define nullptr NULL
#endif
int get_integer_num(const int max, const int min){
//機能:標準入力を数字に変換する。
//引数:戻り値の最大値,戻り値の最小値
//戻り値:入力した数字、エラー時は-1,EOFのときはEOF
char s[100];
char *endptr;
if (nullptr == fgets(s, 100, stdin)){
if (feof(stdin)){//エラーの原因がEOFか切り分け
return EOF;
}
return INT_MIN;
}
if ('\n' == s[0]) return INT_MIN;
errno = 0;
const long t = strtol(s, &endptr, 10);
if (0 != errno || '\n' != *endptr || t < min || max < t)
return INT_MIN;
return (int)t;
}
int getnum_customized(const int max, const int min){
if (max < min) return -1;
int flag0;
bool temp_judge;
do{
flag0 = get_integer_num(max, min);
temp_judge = (INT_MIN == flag0);
if (temp_judge){
system("cls");
puts("再入力してください。");
}
} while (temp_judge);
return flag0;
}
int main(void){
puts("値を入力してください。");
const int flag = getnum_customized(100, 0);
if(EOF == flag){
puts("ファイル終端です");
}
else{
printf("取得した値は%dです。\n", flag);
}
return 0;
}